Sensitivity Analysis
Although the used models are simple there are about 30 parameters that
can be varied. It is therefore important to know which parameters have
a high influence on the results. With the implemented sensitivity
analysis it is relatively easy to determine which parameters are
important for a specific task. But it should be emphasised that the
results of the sensitivity analysis are only valid for the specific
project data, that means sensitivity analysis should be repeated for
each scenario because it depends on the chosen mean parameter values.
REBEKA2 performs a local sensitivity analysis: each parameter is varied
within its range set by the user while all
other parameters are kept constant at their mean values. The number of
calculation points for each parameter can be set by the user. It ranges
from 3 to 11. Default number is 5. If e.g. the lower limit of a
parameter is 9.0 and the upper limit is 11.0, the following 5
calculation points are chosen: 9.0, 9.5, 10.0, 10.5, and 11.0. If p
parameters are varied and n number of calculation points are chosen p
times n simulation runs are executed for the sensitivity analysis.
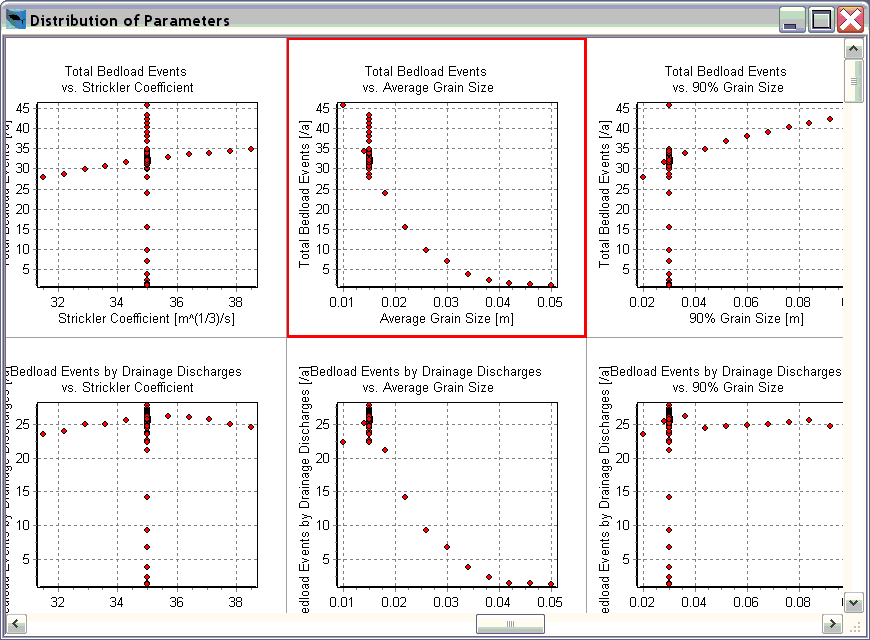
The program creates a matrix of scatter charts. Each row represents a
result and each column a parameter. The following screenshot
shows a part of this chart matrix, for two results (total bedload
events and bedload events caused by drainage discharges) and three
parameters (Manning-Strickler coefficient , average grain size and 90%
grain size of the river bed). It can be seen that the average grain
size is the most important parameter for the number of beload events.
To make it easier to navigate through the sensitvity analysis matrix a
navigation window shows a small copy of the matrix.
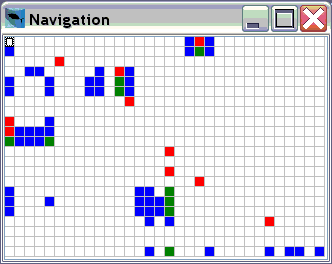
Each pixel in the grid represents a chart with a varied parameter on
the x-axis and a result on the y-axis. The colors indicate how
sensitive a result reacts on the parameter change. Red are very
important parameters, green less important and blue of minor
importants. White indicates parameter with nearly no influence on the
results. The navigation can be changed to another view where a chart
can be selected by its x- and y-axis attributes.
Random Sampling
The choice of parameter values randomly taken from the parameter range
is called random sampling. REBEKA2 allows choosing different sampling
techniques: Random, Latin hypercube and quasi-random sampling. Latin
hypercube and quasi-random distributions are generated by an external
program RANDSAMP from the statistical library UNCSIM (Reichert, 2001). They
create random values which - compared to random sampling - optimally
fill the multi-dimensional para-meter space.
REFERENCES
Reichert P. (2001). UNCSIM - A
program package for uncertainty analysis and Bayesian inference: User
Manual. Dübendorf, Switzerland, EAWAG: 36.